Learning ML with Rust
In the last two years I went incredibly deep professionally with Rust. Now that various LLM Agents have made side projects much faster, I’m going to explore various projects using HuggingFace’s Candle library.
Originally I was taking courses on ML but realized it would just be better to learn by doing, as well as watching a bit of youtube courses. It’s always crazy how fast you learn just by doing things! Even when Claude is writing the code for you, you’re still learning via the design process.
My first one is birbs - a simple project to classify bird images. Felt like an easy way to start.
Originally I was taking courses on ML but realized it would just be better to learn by doing, as well as watching a bit of youtube courses.
It’s a 3 layer convulational neural network - already thats a big set of words!
The short explanation seems to be that the 3 layers are responsible for automatic, rather than manual, feature detection. A feature is an inpuit into the machine learning process.
It seems like the Convulational layers are responsible for dividing and learning on the image based on grids. ML has a lot of technical jargon that seems required to be able to communicate well.
The application has a dataset loader, a training loop and the actual network that is being trained.
Of course you also need to acquire the dataset, for that I chose this. I’m not going to do species identification yet, just seemed like a good dataset to use. It’s only 10 Gb, so easy enough to fit on my Macbook Air.
Interesting that there’s no simple way to host a publically available dataset I suppose other than Dropbox where it’s hosted. Kaggle has some stuff as well, maybe you can integrate with kaggle via an SDK and an API key to have your programs training dataset (and the hash) stored in source.
I am enjoying learning this way by doing - it’s kind of how you can easily learn the “shape” of a domain, like the places and the problems those places have. Powerful.
Like data loading - ok these datasets are large so need to be hosted on S3, and you need to collect them, and you need to vet and load them. All things that are obvious once you’ve worked on this for a few minutes, but unclear at first.
To run the model: cargo run --release
First the model loads the images, then it proceeds through the epochs. Through each training epoch it processes all the batches.
An interesting question, is it using my macbook air’s onboard GPU?
Answer: No - it’s using the Apple Metals API for interacting with the Apple GPUs.
My first run went poorly - Claude had adapted my code to classify bird species which I did not want it to do, as I wasn’t confident in the size of my dataset.
I then decided to change it to be a binary classifier (yes/no) where it would decide if an image was a bird or…something else. The hard part is picking that something else.
Kaggle datasets seemed overall bad an unmaintained. HuggingFace datasets seems better.
Using this Honey dataset for the “not bird” images since it seems like a wide variety of images to use: https://huggingface.co/datasets/Open-Bee/Honey-Data-15M
It’s good to see the ML community also uses Parquet. I have experience there so things translate pretty quickly.
Working on downloading the hugging face dataset, its definetly clear that assembling the dataset (is that pretraining?) is a huge challenge. And for the dataset providers, thats a lot of bandwidth they’re providing for free for people like me to play around. Curious what hugging face’s business model is
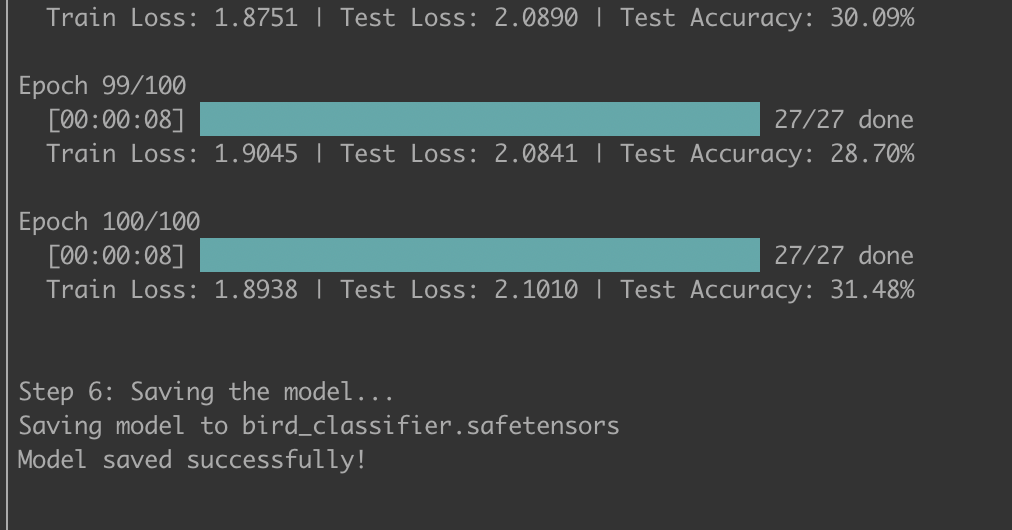
Ok, so I added in auto-loading a non-bird dataset, as well as a neat little TUI so I could see progress better. And the first run was 100% accurate from the start! Debugged with Claude, this was because of a dataset imbalance, where we had 18x more samples of non-bird so the model was cheating by always guessing non bird. Tricky little model.
Added a class balancer so that we’d have equal numbers of bird and non bird photos.
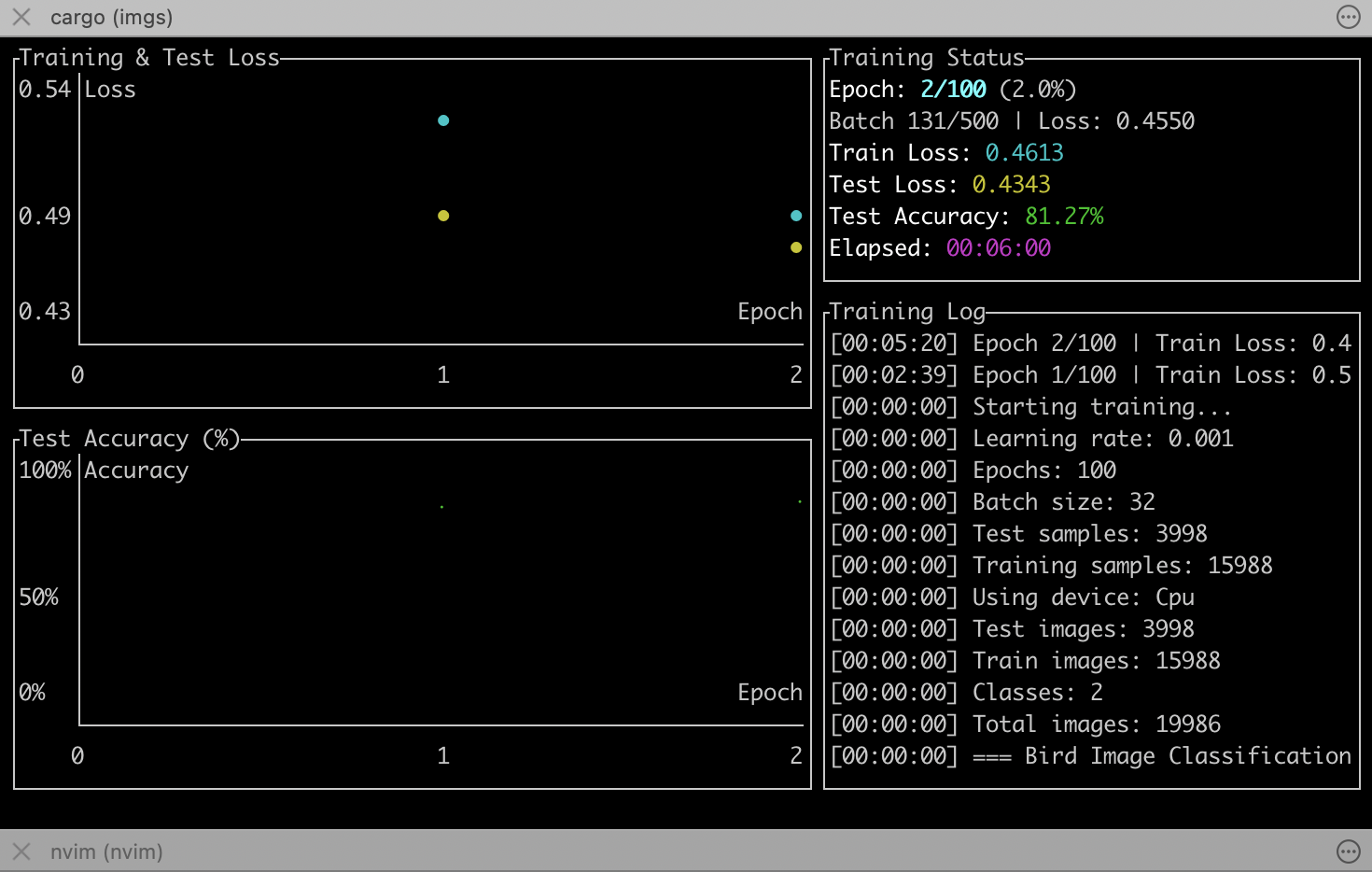
Kicking off the model a second time, you can see how slow it is. You can imagine what on-call for this is like - somehow paging if the loss function goes haywire, if you’re dealing with mega training runs where there’s a lot of wasted utilization on the line.
Loss is going down, so I’m going to let it run overnight and see what happens in the morning: